





HTTP 1.1 is a well-known hypertext protocol for data transfer. HTTP messages are encoded with ISO-8859-1 (which can be nominally considered as an enhanced ASCII version, containing umlauts, diacritic and other characters of West European languages). At the same time, the message body can use another encoding assigned in "Content-Type" header. But what shall we do if we need to assign non-ASCII characters not in the message bodies, but in the header? Probably the most well-known case is setting a filename in "Content-Disposition" header. It seems quite a common task, but its implementation isn’t obvious.
TL;DR: Use the encoding described in RFC 6266 for "Content-Disposition" and transliterate to Latin in other cases.
Introduction to encodings
The article mentions US-ASCII (usually named just ASCII), ISO-8859-1 and UTF-8 encodings. Here is a small intro to these encodings. This paragraph is for developers who rarely work with these encodings or doesn’t use them at all, and have partially forgotten them. If you’re not one of them, skip this part without hesitation.
ASCII is a simple encoding with 128 characters, including Latin alphabet, digits, punctuation marks, and utility characters.
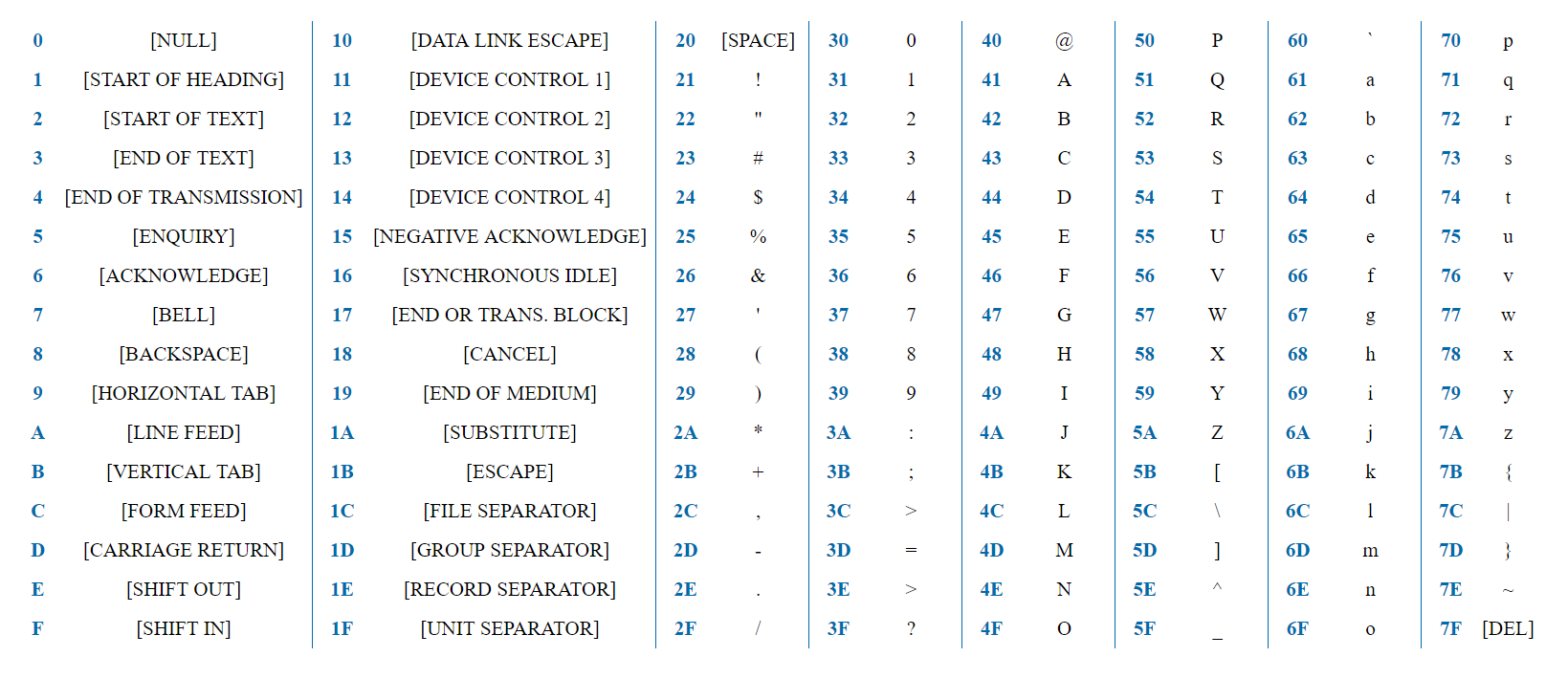
7 bits is enough to represent any ASCII character. The word "test" in HEX representation would look as 0x74 0x65 0x73 0x74. The first bit of any character would always be 0, as the encoding has 128 characters, and a bite gives 2^8 = 256 variants.
ISO-8859-1 is an encoding aimed for West European languages. It has French diacritic, German umlauts, etc.
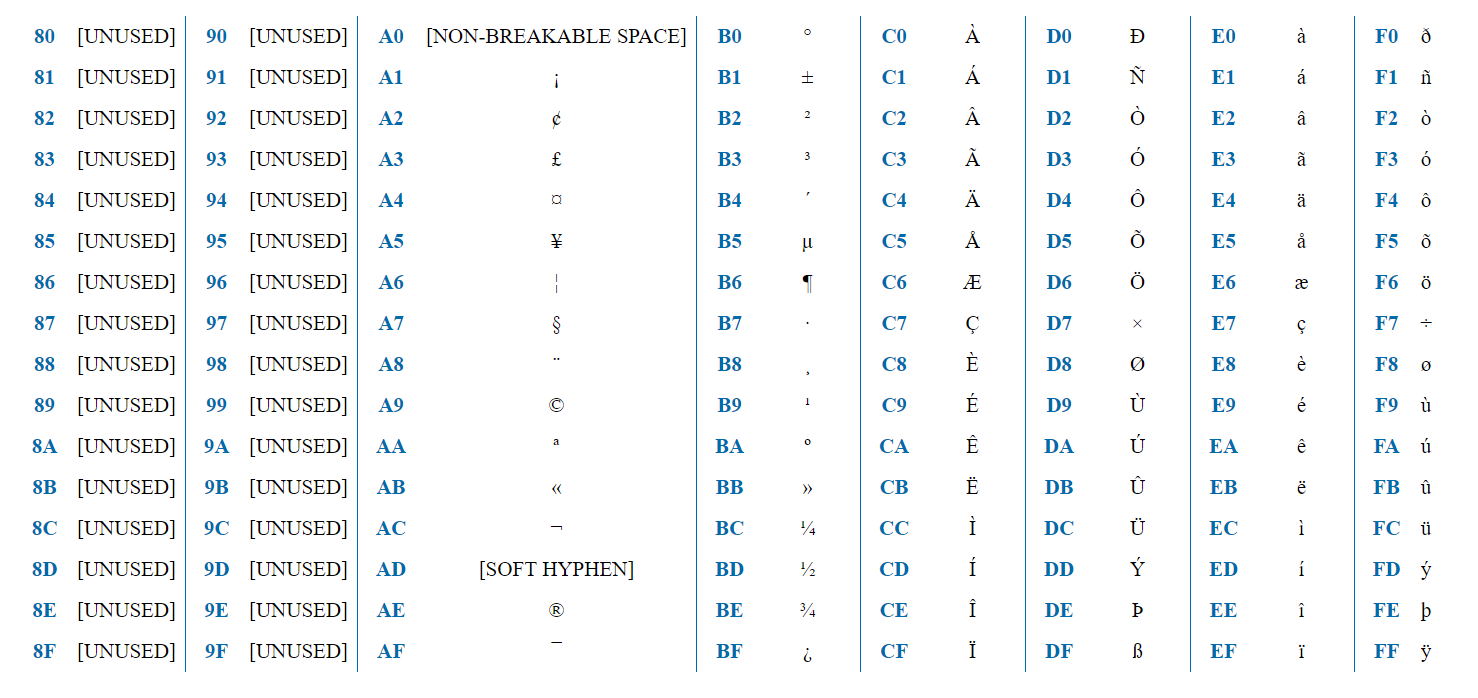
The encoding has 256 characters, thus, can be represented with 1 byte. The first half (128 characters) fully matches ASCII. Hence, if the first bit = 0, it’s a usual ASCII character. If it’s 1 - we recognize a specific ISO-8859-1 character.
UTF-8 is one of the most famous encodings alongside with ASCII. It is capable of encoding 1,112,064 characters. Each character size is varied from 1 to 4 bites (previously the values could be up to 6 bites).


The program processing this encoding checks the first bit and estimates the character size in bytes. If an octet begins with 0, the character is represented by 1 byte. 110 - 2 bytes, 1110 - 3 bytes, 11110 - 4 bytes.
Just like in case with ISO-8859-1, the first 128 well match ASCII. That’s why texts using ASCII characters will look absolutely the same in binary representation, regardless of the encoding used: US-ASCII, ISO-8859-1 or UTF-8.
UTF-8 in message body
Before we proceed to headers, let’s see how UTF-8 is used in message bodies. For that purpose we use "Content-Type" header.

If "Content-Type" isn’t assigned, a browser must process messages as if they were in ISO-8859-1. A browser shouldn't try to guess the encoding, and it certainly shouldn’t ignore "Content-Type". So, if we transfer UTF-8 messages, but do not assign encoding in headers, they will be read as if they were encoded with ISO-8859-1.

Entering an UTF-8 message in a header’s value
In case of a message body, everything’s rather simple. A message body always follows a header, so there’re no technical problems here. But what shall we do with headers? The specification claims directly, that the order of headers in messages doesn’t matter. I.e. it’s not possible to assign an encoding for one header via another.
What if we just write a UTF-8 value into a header? We saw that with such a trick, applied to a message body, the value will be read in ISO-8859-1. Therefore, we can assume that the same will happen to a header. But no, it won’t. In fact, for most, maybe even for all, cases such a solution will work out. Such cases include old iPhones, IE11, Firefox, Google Chrome. The only browser refusing to read such a header, of all the browsers I had when writing this article, was Edge.

Such behavior is not described in specifications. Probably, the developers of browsers decided to go easy on other developers and detect the UTF-8 encoding of messages automatically. Generally speaking, it’s a simple task. Check the first bit: if it’s 0, then it’s ASCII, if 1, then it’s probably UTF-8.
Isn’t there anything in common with ISO-8859-1, in that case? Actually, almost none. Let’s use a UTF-8 character of 2 octets as an example (Russian letters are represented by two octets). In binary representation, the character will look the following way: 110xxxxx 10xxxxxx. In HEX representation: [0xC0-0x6F] [0x80-0xBF]. In ISO-8859-1 those symbols can hardly be used to express something sensible. Therefore, there’s very little chance that a browser will decode a message in a wrong way.
However, you can face some problems when trying to use this method: your web server or framework can simply forbid writing UTF-8 characters into a header. For example, Apache Tomcat enters 0x3F (question mark) instead of UTF-8 symbols. Of course, this restriction can be circumvented, but if an application slaps you on the wrist and doesn’t let you do something, then you probably shouldn’t do it.
No matter if your framework or server forbids or lets you write UTF-8 messages in a header, I don’t recommend doing that. It’s not a documented solution and can stop working in browsers at any moment.
Transliteration
As I see it, transliteration is a better solution. Many popular Russian resources don’t mind using transliteration in filenames. It’s a guaranteed solution which wouldn’t break with new browser versions release and which isn’t necessary to be tested separately on each platform. Although, you should certainly think of the way of transferring all the possible range of characters, which can be not so easy. For example, if an application is aimed to a Russian audience, the filename can contain Tatar letters ә and ң, which should be somehow handled, not just replaced with "?".
RFC 2047
As I’ve already mentioned, Tomcat didn’t let me enter UTF-8 in a message header. Is this feature mentioned in Javadocs for servlets? Yes, it is:
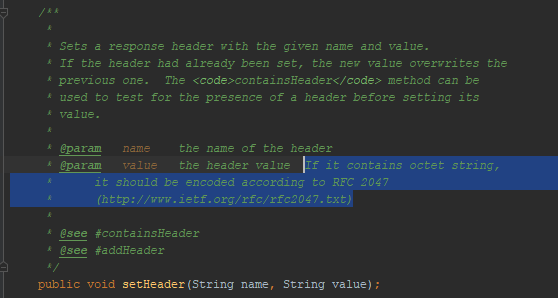
It mentions RFC 2047. I tried to encode messages using this format - the browser didn’t get the idea. This encoding method doesn’t work for HTTP anymore. However, it used to. For example, here's a ticket on deleting this encoding support from Firefox.
RFC 6266
The ticket mentioned above says, that even after the support of RFC 2047 stops, there’s still a way to transfer UTF-8 values in downloaded files names: RFC 6266. From my point of view, today it’s the most optimal and correct decision. Many popular Internet resources use it. We in Jmix also use this RFC for "Content-Disposition" generation.
RFC 6266 is a specification describing the use of “Content-Disposition” header. The encoding itself is closely described in RFC 8187.
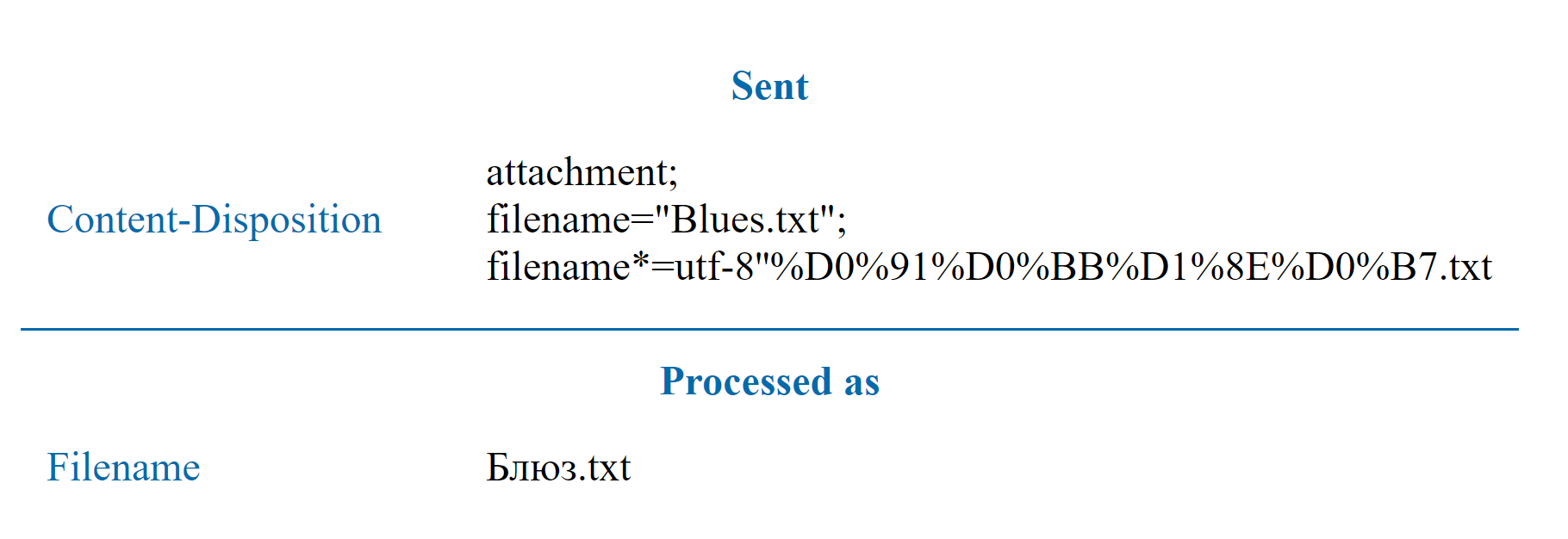
Parameter “filename” contains the name of the file in ASCII, “filename*” in any other necessary encoding. If both attributes are defined, “filename” is ignored in all modern browsers (including IE11 and old Safari versions). The oldest browsers, on the contrary, ignore “filename*”.
In this encoding method, first you assign the encoding in a parameter, after '' comes the encoded value. Observed characters of ASCII don’t require encoding. Other characters are just written in hex representation with "%" before each octet.
What should be done with other headers?
Encoding described in RFC 8187 isn’t generic. Of course, you can enter a parameter with * prefix in a header, and it would probably work for some browsers, but specification dictates not to do so.
Currently, in each case, where UTF-8 is supported in headers, there’s a direct mention of the relevant RFC. Besides "Content-Disposition" this encoding is used, for example, in Web Linking and Digest Access Authentication.
It should be taken into account that the standards of this area are constantly changing. The usage of above-mentioned encoding in HTTP was offered only in 2010. The usage of this encoding in the very "Content-Disposition" was committed in the standard of 2011. Despite the fact that these standards are only on "Proposed Standard" stage, they are supported everywhere. It is quite possible that new standards are going to appear, the standards that will allow us to work with various encodings in headers more consistently. So, we only need to follow the news about the HTTP standards and their support level on the browser side.